Importing processed microarray data into R from GEO
Overview
Teaching: 10 min
Exercises: 10 minLearning Objectives
Be able to obtain data from GEO, including processed and raw data.
Be able to explain and use the differences between GEO data types.
Understand the concept of the ExpressionSet class of objects.
In the class, we learned how the basic requirements of a complete data object for gene expression
microarray studies consists of a tall, skinny matrix (for the experimental measurements) and a
short, wide table (to describe the experiment). The Bioconductor class for this type of data is an
ExpressionSet.
In this lesson we will be creating these objects in R from data available at GEO.
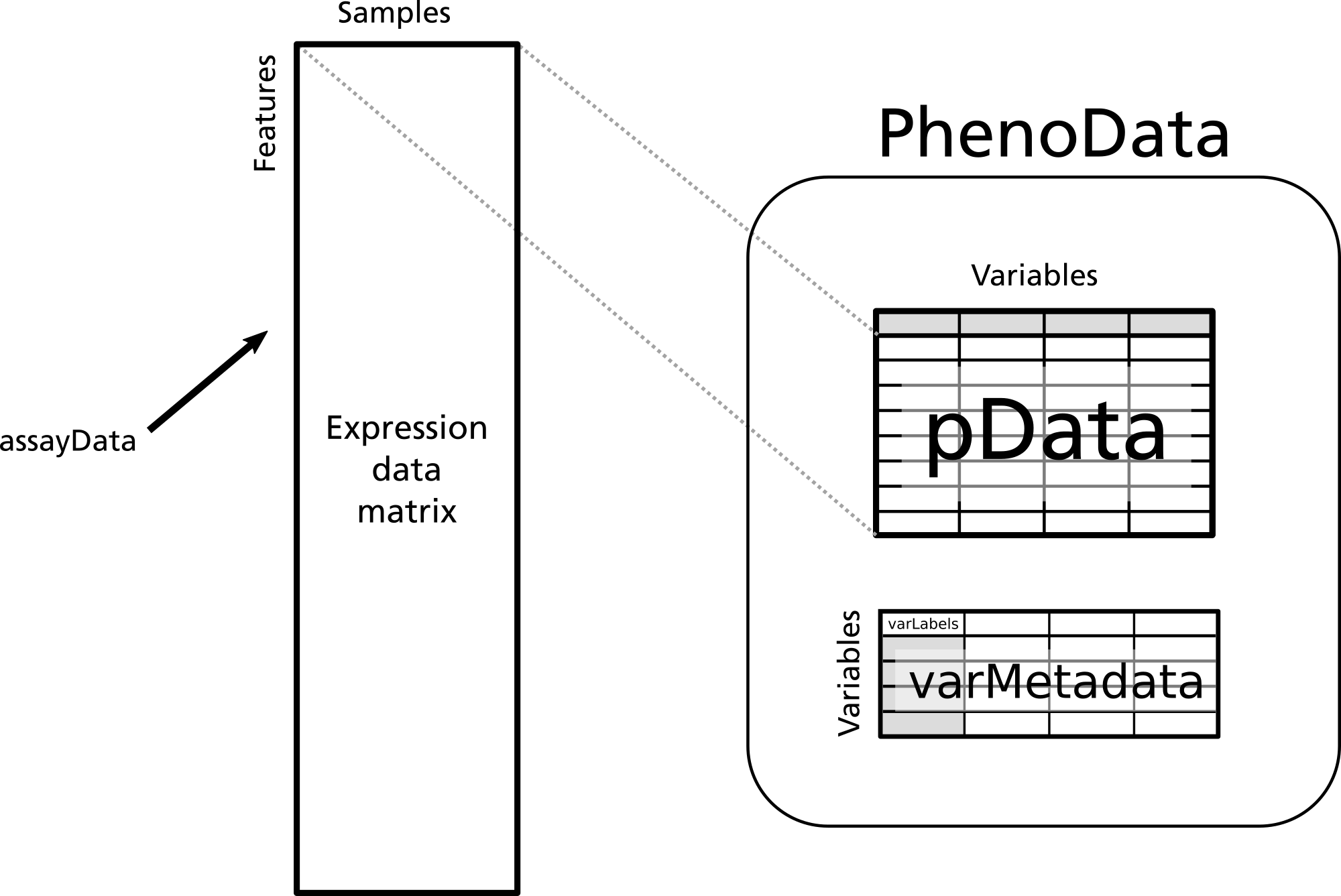
The ExpressionSet class
The ExpressionSet class of objects are commonly used to store microarray experiment data. A typical ExpressionSet class object contains the following data:
- assayData
- raw or processed intensities, where each row corresponds to one probe and each column corresponds to one sample
- phenoData
- experimental meta-data, where each row corresponds to one sample.
- featureData
- This is optional annotation of the features (e.g., genes or transcripts) measured in an experiment.
- annotation
- a character vector specifying the platform name
The first data set
Data for this lesson is taken from GEO (accession ID: GSE33146). The experiment was on a cancer cell line grown in culture. Cells are grown in either MEGM (where they retain an epithelial phenotype) or SCGM (where they undergo reversible epithelial-mesencymal transition, or EMT). Gene expression analysis using the hgu133plus2 microarray was performed to identify genes associated with the EMT process.
Getting processed data from GEO into R
Before any analysis, we need to get the data into R. If you navigate to GSE33146, you will see that several different file formats are available for download.
The GEO file types
- SOFT files
- The SOFT file format is commonly used by submitters to GEO. It contains a lot of information about the experiment (MIAME compliance), and also contains the estimates for each gene or transcript, in a custom defined file format.
- MINiML file
- The MINiML file format uses XML, a computer-readable markup language. This has the same information as SOFT, but in a different format.
- Series matrix file
- The matrix file is meant to be readable directly into a spreadsheet. Generally these files don’t have all the information provided by SOFT, but are easy to work with.
- Supplemental files
- The
.CELfiles have the original, unprocessed data. Since we want to process it ourselves, that’s what we’ll need.
Download the files or query them directly using GEOquery
The GEOquery package (definitely try browseVignettes('GEOquery')) provides tools for reading files directly from GEO based on the accession.
GEOquery works for different kinds of GEO data, including Samples (GSM), platforms (GPL), data sets, (GDS), and series (GSE).
These data appear complicated.
GEOquery, like other Biconductor packages, creates data objects that seem somewhat complicated. If you are used to simple R lists, vectors, and data frames, the data structures may seem overwhelming. Keep in mind that these data stuctures, regardless of how complicated they are, are basically compositions of data structures you already know: lists, vectors, matrices, and data frames.
Getting a single GSM object for a single sample
We can create a single GSM object of a single sample with a call to getGEO (I’m using an example from the same GSE).
library(GEOquery)
gsm <- getGEO('GSM820817')
## What methods are available to call on this class of data?
methods(class=class(gsm))
[1] Accession Columns dataTable Meta show Table
see '?methods' for accessing help and source code
## The Table method shows the estimates
head(Table(gsm))
ID_REF VALUE
1 1007_s_at 11.502651
2 1053_at 9.861017
3 117_at 6.299005
4 121_at 8.632274
5 1255_g_at 3.721331
6 1294_at 7.376385
## The Meta method shows the experimental design, etc.
head(Meta(gsm))
$channel_count
[1] "1"
$characteristics_ch1
[1] "cell line: Human breast cancer-derived cell line DKAT"
[2] "culture medium: MEGM"
$contact_address
[1] "MSRB Room 217, Research Dr."
$contact_city
[1] "Durham"
$contact_country
[1] "USA"
$contact_department
[1] "Pharmacology and Cancer Biology"
As you can see, the Table method returns numeric estimates for each probe (which is what we will eventually get after pre-processing), while the Meta method gives us information about our experiment.
Why does this GSM appear in two series?
One of the
Meta()entries shows that the sample from GSE33146 actual belongs to two series. What is the difference between them?Solution
Meta(gsm)[['series_id']][1] "GSE33146" "GSE33167"Look up GSE33167 on the GEO web site. The series GSE33167 is a super-series composed of two series: the one we are looking at and another series comparing baseline expression among triple-negative breast cancer cell lines.
Retrieving the whole GSE as a list of ExpressionSets
The function getGEO() with a GSE identifier as a sole argument will download the series matrix files from GEO and return them as a list of ExpressionSet objects. In many cases, there will only be one experiment for a series, so the list will contain a single ExpressionSet, which can be retrieved as the first member of the list.
library(GEOquery)
gse33146 <- getGEO('GSE33146')
Found 1 file(s)
GSE33146_series_matrix.txt.gz
length(gse33146)
[1] 1
class(gse33146[[1]])
[1] "ExpressionSet"
attr(,"package")
[1] "Biobase"
gse33146 <- gse33146[[1]]
Retrieving the whole GSE by parsing the SOFT file
When getGEO() is run with the named argument GSEMatrix=FALSE, it does not parse the Series Matrix files but does parse the SOFT files. The advantage of this method is that the SOFT files may contain more information than the series matrix files, but a disadvantage is that it is much slower and the resulting object is not a list of ExpressionSets. However, parsing the Series Matrix can also introduce errors; parsing the SOFT file is less error-prone.
The GSE is the most complicated object retrieved by getGEO, because a series is composed of sample (GSM) and platform (GPL) objects. Each is accessed by a list: GSMList and GPLList. You can download the whole series into an R object by accession, but you can also download the file outside of R and read it in as a local file.
library(GEOquery)
## if we have a good connection to the internet, we can download it directly from GEO
gse2 <- getGEO('GSE33146',GSEMatrix=FALSE)
# If it's available on a local file system, we can read the file directly
##gse2 <- getGEO(filename='data/GSE33146_family.soft')
names(GSMList(gse2))
Using the processed data from a GSE or GDS as an R ExpressionSet
For a GEO Data Set (GDS) The GEOquery package provides a function
GDS2eSetto converta a GDS directly to an ExpressionSet object. This function uses the processed data available on GEO, not the raw data.There is no corresponding
GSE2eSetfunction because a single GEO Series can contain data from multiple platforms, and an ExpressionSet object is data from one platform.
Get the second data set
Our second data set contains 12 samples, and is found in GSE66417. Retrieve the processed data into an ExpressionSet object.
Solution
gse66417 <- getGEO('GSE66417')Found 1 file(s)GSE66417_series_matrix.txt.gzlength(gse66417) # this should be a list of length 1[1] 1gse66417 <- gse66417[[1]]
Key Points
GEO data types have enough similarities to allow data access, but enough differences to require specific type-specific steps. and analysis.
The ExpressionSet class of object contains slots for different information associated with a microarray experiment.